
Застосування нейромережі Stable Diffusion в роботі з казуальною графікою. Досвід і лайфхаки


Усім привіт, мене звуть Олена Саміло, я Lead 2D Artist компанії Smart Project. Вже близько року ми з командою тестуємо нейромережу Stable Diffusion для більш ефективного виконання робочих цілей. Сьогодні я хочу поділитися особливостями такої взаємодії та наочними результатами. У цій статті ви знайдете цікаві для себе лайфхаки та відмітити чи стане для вас корисним застосування AI в роботі.
Коли по верхньому інтернету пронеслося цунамі штучного інтелекту, яке на перший погляд відбирає скоринку хліба у простих художників й обіцяє переворот в індустрії, генеративний арт привернув і мою увагу. Особливо, після того як друзі почали активно ділитися першими спробами в нейромережі Midjourney, мене цей тренд також не оминув.
Кіберпанк-тяночки, створені за пару хвилин в один клік, вражали уяву. Але я зрозуміла, що Midjourney не підходить для робочих завдань із казуальною графікою, так як результати все одно вимагають правок через труднощі з відтворенням потрібного стилю, а також через те, що цю AI не можна навчити своєї стилістики.
Наступні дні пішли на вивчення інструментів, технологій та технічних аспектів різних AI. Я з головою поринула у пошуки технології, яка б більше відповідала нашому запиту. У цьому процесі я й натрапила на інформацію про нейромережу Stable Diffusion (далі SD), що має відкритий код і дозволяє взяти вже створену модель за основу, додати свої зображення і навчити на датасеті модель необхідного стилю або відтворення конкретного персонажа. У нас на проектах до цього часу якраз накопичилося багато контенту в потрібному стилі, який можна було використовувати для датасетів.
Ще одна особливість Stable Diffusion яка мене зацікавила те, що різноманіття налаштувань та їх встановлення відбувається локально на комп’ютері. Найпопулярніший веб-інтерфейс для цієї нейромережі від AUTOMATIC1111, але працювати можна й через інші інтерфейси, це справа вибору конкретного користувача. Серед варіантів є Easy Diffusion, Vlad Diffusion, NMKD Stable Diffusion GUI.
Усвідомивши потенціал Stable Diffusion, ми зіткнулися з технічними складнощами. Обмежені обчислювальні ресурси стали проблемою, так як не всі в команді мають однаково потужне обладнання. Тому найбільш ефективним рішенням стало виділення сервера, що обробляє всі генерації.
Але SD не призначений для одночасного використання кількома користувачами й також не підтримує кілька графічних карт, отже прорахунки все одно йшли послідовно, на відміну від Easy Diffusion, який розраховано на багато користувачів системою і дозволяє об’єднати обчислювальні потужності декількох відеокарт, збільшивши швидкість прорахунків генерацій і давши можливість отримувати зображення більш високої роздільної здатності.
Штучний інтелект може бути використаний для різних завдань:
- Для R&D проектів
- Для швидкої верифікації гіпотез та тестування нових ідей
- Для створення контенту
- Для оптимізації часу розробки контенту
- Для генерації ідей та концептів, що сприяє зменшенню часу, що витрачається на пошуки варіантів дизайну, композиції, рішень щодо кольору та освітлення.
У стані творчого ступору і при «страху білого листа», AI здатний дати хороший старт і полегшити муки народження концепту). І навіть ПЗ взяли це на своє озброєння, даючи художнику нариси своїх ідей, що полегшує порозуміння.
Рендер
За допомогою Stable Diffusion можна прискорити процеси рендеру. Наприклад, рендер казуального персонажа, на який раніше могло піти до трьох днів, зараз можна зробити за півтора дні. AI відмінно справляється з рендером об’єктів у певному стилі, покращенням якості, збільшенням роздільної здатності зображення, доповненням відсутніх меж зображення, заміною об’єктів, вписуванням об’єктів в оточення, клінапом і т.д.
Також можна пропускати через AI роботу художника для підвищення якості рендеру, виправлення помилок освітлення, якщо задати невисокі значення параметрів CFG Scale та Denoising strength. Але для створення якісної графіки необхідно більше, ніж просто натискання кнопки та підбір правильних ключових слів для опису зображення, які називаються токенами. Це включає уміння скомпілювати все в єдину композицію, додавати або перемальовувати деталі, які можуть викликати труднощі у AI, знання про те, як виправити неправильну анатомію, і відредагувати логіку на рівні концепту, так як мережа може створювати красиві, але не завжди логічні об’єкти.
Зараз робота зі Stable Diffusion звелася до таких етапів:
Перший — це навчання нейромережі на потрібний нам стиль. У Stable Diffusion є кілька способів навчання: Dreambooth, Textual Inversion, LoRA.
Наприклад, стоїть завдання генерувати інтер’єр у відповідному стилі. Для цього необхідно:
- зібрати датасет зображень у потрібній стилістиці; нарізати всі зображення на невеликі частини так, щоб кожен фрагмент був елементом інтер’єру;
Примітка. Вважається, що найкращий результат нейромережі видає при генерації квадратних зображень 512×512 px, тож я навчалася саме на такому розмірі. Якщо потрібно зробити прямокутні картинки, рекомендується робити одну зі сторін або рівною 512 px, або зменшити чи збільшити це значення в два рази до 256 або 1024 точок відповідно. Проте краще навчати на зображеннях формату 512×512 px.
Друге. Робимо опис до кожної картинки, це можна зробити автоматично, прогнавши їх за допомогою функції Preprocess Images у SD. На цьому етапі важливо оцінити вірність опису та скоригувати його за потребою. Якщо цього не зробити, то при подальшій роботі нейромережа створюватиме некоректні генерації. Після навчання нейромережі отримуємо необхідний стиль. І його можна передавати для використання колегам для досягнення максимальної одноманітності підсумкових зображень.
Завдяки відкритому коду Stable Diffusion має дуже багато моделей: для імітації різних художніх стилів, для реалізму, для аніме і для створення архітектурних ескізів. Ми використовуємо одну з найпопулярніших універсальних моделей Deliberate 2.0. Робити генерації можна за текстовими запитами або методом img2img, даючи вихідне зображення. Нейромережа її обробляє під стилістику, на яку модель навчили. При цьому найкращий результат виходить при використанні цього методу у зв’язку з ControlNet. ControlNet призначена для кращого контролю генерації Stable Diffusion. Дозволяє контролювати та спрямовувати генерацію різними методами. Задаючи контури, позу, карту глибини чи нормалей. Є кілька додаткових нейромереж, які працюють спільно з SD і використовуються як додаток, а не самостійна архітектура. Для Automatic1111 є розширення sd-webui-controlnet.
Розглянемо метод на прикладі конкретної задачі створення карти прогресу для нашої програми:
- Спочатку митець створює концепт із готовим кольоровим рішенням по всіх об’єктах та чистовим лайном.

Для рендеру в SD зберігаємо окремо об’єкти та персонажів на нейтральному фоні, фон такого формату також бажано нарізати на складові, що вписуються в квадратний формат. Далі пропускаємо всі зображення, які потрібно доопрацювати через стиль у Stable Diffusion у зв’язці з ControlNet. Складання промта (текстовий запит, що включає набір характеристик, які дозволяють нейромережі видати очікуваний результат) для Stable Diffusion трохи відрізняється від того, як це робиться в Midjorney.
Нейромережа Midjorney краще розуміє складні зв’язкові пропозиції. Stable Diffusion краще розуміє окремі слова або поєднання з 2-3 слів, розділені комами. Також окремо взятим токенам можна додавати вагу за допомогою дужок «()», з їх допомогою ми даємо зрозуміти нейромережі, що цей параметр важливий і на ньому варто акцентувати увагу.
Отримуємо приблизно такий результат:

Отримані зображення віддаються художнику на доопрацювання та на фінальному етапі отримуємо готову карту:

Другий метод використання за текстовим запитом також у зв’язці з ControlNet і, наприклад, іншій нейромережі.
Для початку створюємо через SD, Dall-E або Midjourney (даний приклад був створений в Dall-E 3) те, що нам потрібно, переводимо його в ControlNet і отримуємо контури лініями, пишемо промт + Лору на потрібний нам стиль. Підсумок ми отримуємо результат дуже швидко і з потрібною нам стилістикою.
Для покращення результату можна почистити ЧБ зображення або на його основі створити кольоровий скетч:
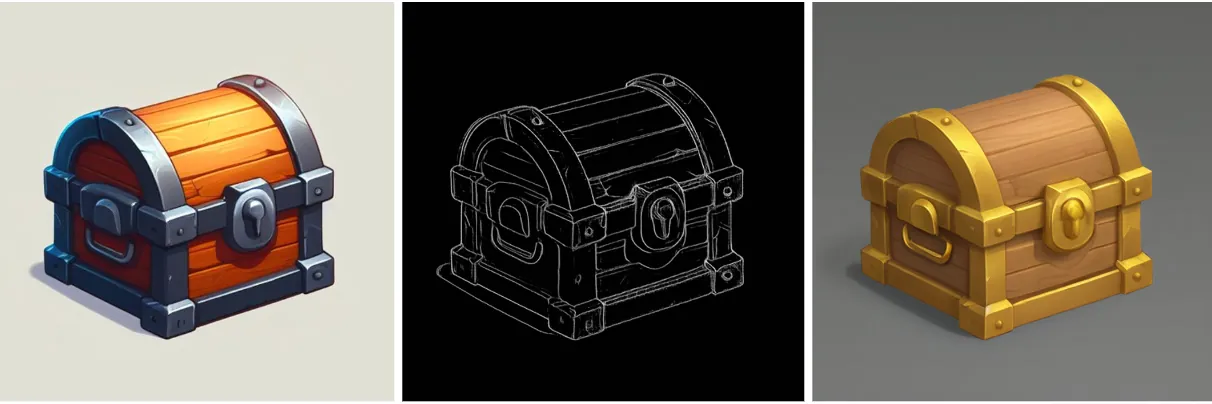
Зв’язка «Stable Diffusion + зручний сервіс з потужними серверами + метод image-to-image» заощадить арт команді багато часу, якщо заздалегідь все підготувати: донавчити модель на власному контенті. Якщо підсумувати, поки нейромережі не можуть замінити кваліфікованого художника, але можемо її використовувати як ще один інструмент: крім іконок, можна генерувати допоміжні матеріали, патерни, плакати, фони та частини фонів, рендерувати персонажів та фони по скетчах. Згенерувати їх у потрібній стилістиці та колажувати — набагато швидше.
Нам ще зарано масштабувати ці підходи на всю команду. Тому зараз ці інструменти залишаються інтегрованими не на всі 100% у наші процеси — ми ще вивчаємо нові перспективи та можливості, які дає нам штучний інтелект у сфері графіки. Але думаю, що нейромережі дозволять художникам виконувати комплексніші завдання. І за ту саму кількість часу ми зможемо робити складніші речі, що є безумовною перевагою.
Всім дякую! Рада була поділитися нашим досвідом і сподіваюся, що матеріал був для вас корисним.

